Understand natural language processing
How Google's NLP API can help you on your next web project.

Websites and apps can have various moving parts including front end creative, server-side processing, APIs and data storage. AI can plug in any of these components.
On the front end, you can connect voice commands, chatbot interfaces or reactive WebGL creative elements. On the back end, databases use intelligent algorithms to maximise speed and analysis. APIs can provide a layer of abstraction from a wide range of AI functions, from predictions to collective training.
If you're just starting out as a developer and need some pointers, find out how to make an app, or we can help you choose which website builder, web hosting service and cloud storage to use.
Natural language
Natural language processing (NLP) focuses on the interactions between machines and human languages. It is the objective of NLP to process and analyse vast amounts of language data to improve natural communication between humans and machines. This field of AI includes speech recognition, understanding language and generating natural language. Our focus will be on understanding natural language, the process of analysing and determining the meaning or intent of a text.
There are several concepts common to NLP:
- Detecting language – Understanding which language is being used in the text is fundamental to knowing which dictionaries, syntax and grammar rules to use in analysis.
- Entity extraction – Identifying the key words in phrases, how relevant or salient they are to the overall text and determining what the entities are, based on training or knowledge bases.
- Sentiment analysis – Assessing the general level of 'feeling' in a text. Is it generally positive or negative? Also, sentiment related to each entity. Does the statement reflect positive feelings or negative ones about the 'subject'?
- Syntactic analysis – Understanding the structure of the text. Identify attributes such as sentences, parts of speech (e.g. noun, verb), voice, gender, mood and tense.
- Content classification or categorisation – Organising the content of the text into common categories to more efficiently process them. For example, New York, London, Paris, Munich are all 'locations' or 'cities'.
There are numerous technical approaches to parsing and processing the data. Regardless of which NLP tool you use, you will have to tackle the common steps of parsing and analysis. Typically text is separated into logical chunks. These chunks are analysed against trained data or knowledge bases and assigned values, usually ranging from 0.0 to 1.0 to reflect the level of confidence in the analysis.
Google's Natural Language API
We'll be using the new Natural Language API developed by Google for this tutorial. There are numerous APIs available but Google's has some nice advantages, including cloud computing, speed, an incredibly large user base and machine learning. Google's search engines and tools have been using AI for years. So you're harnessing all that experience and learning by using its public-facing services.
Get the Creative Bloq Newsletter
Daily design news, reviews, how-tos and more, as picked by the editors.
APIs incorporate easily into any project. This saves a lot of time versus hand-coding your own NLP. Its abstracted Restful API enables you to integrate with almost any language you wish through common cURL calls or one of the numerous SDKs available. There are a few tricks to getting set up but we'll work through it one step at a time.
Click on the icon at the top-right of the image to enlarge it.
01. Create new Google Cloud Project
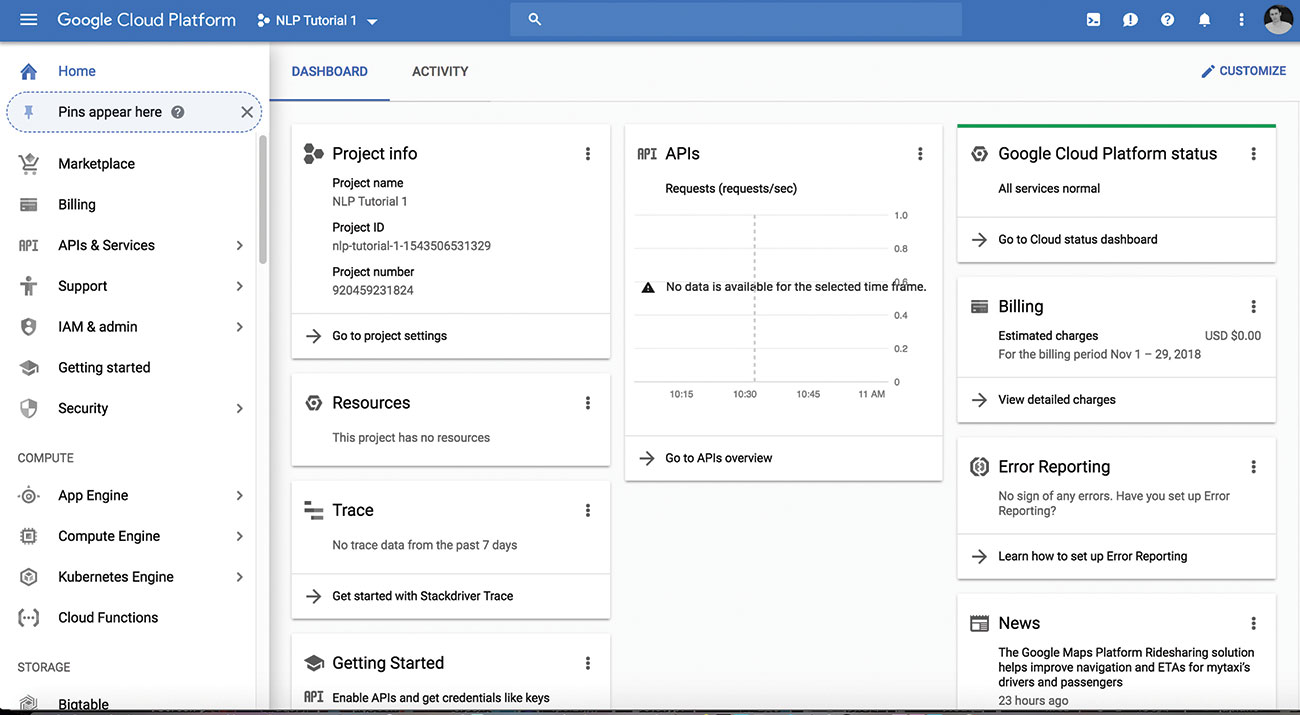
Go to the Google Cloud Platform Console and create a new project or select an existing one to work with. The service is free to use until you start making a large volume of API requests. You may need to associate billing info with the account when you activate the API but this is not charged at low volume and you can remove the services after you are done testing if you wish.
02. Enable the Cloud NL
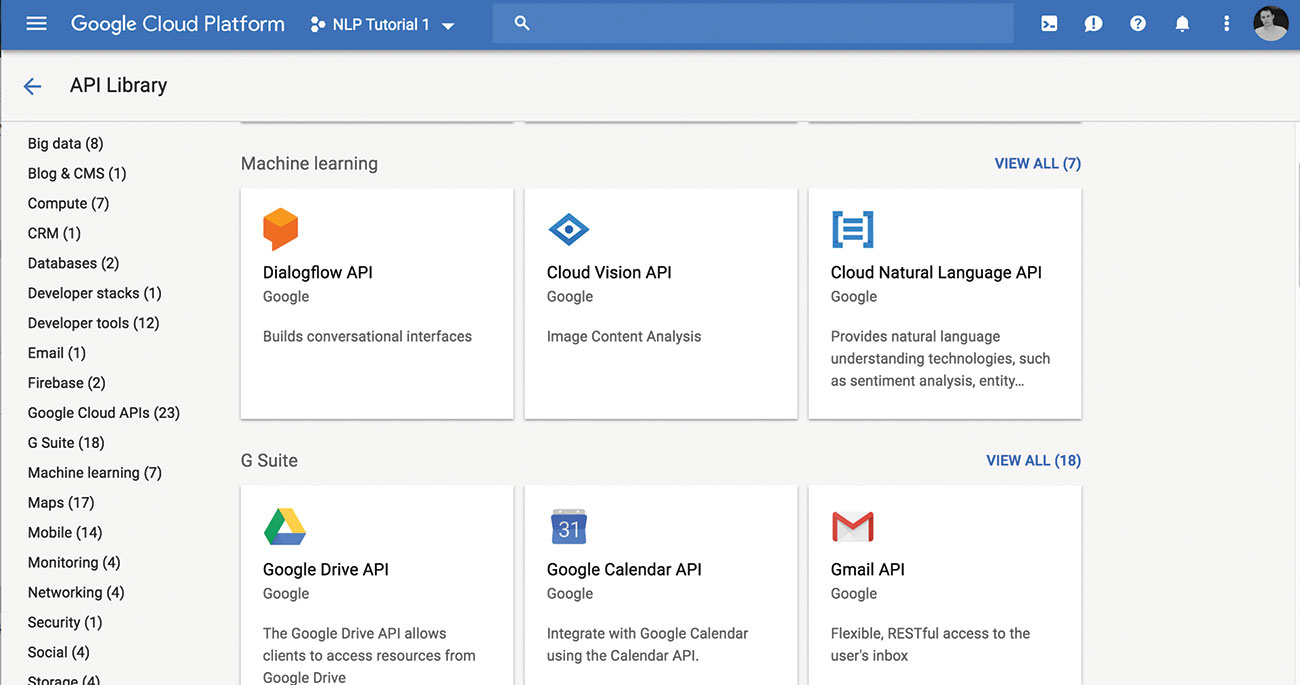
Browse to the API library and select the NL API. Once enabled you should see a little green check and the message 'API Enabled' beside it.
03. Create a service account
You'll need to set up a service account for this service. Since we are going to set up usage like a typical service, this is the best practice. It also works best with authentication flow.
04. Download private key

Once you have a project with the API enabled and a service account you can download your private key as a JSON file. Take note of the location of the file, so you can use it in the next steps.
If you have any problems with the first few steps there is a guide here that helps, which ends with the download of the JSON key.
05. Set environment variable
Next, you need to set the GOOGLE_APPLICATION_CREDENTIALS environmental variable, so it can be accessed by our API calls. This points to your JSON file you just downloaded and saves you having to type the path every time. Open a new terminal window and use the export command like so:
export GOOGLE_APPLICATION_CREDENTIALS="/Users/username/Downloads/[file name].json"Replace the [file name] with your private key file and use the path to your file.
On Windows you can do the same thing via the command line, like this:
$env:GOOGLE_APPLICATION_CREDENTIALS="C:\Users\username\Downloads\[FILE_NAME].json"Note: If you close your terminal or console window, you may need to run that again to set the variable.
06. Make a call to the API
Now you're ready to dig into using the API and see NLP in action. You'll use cURL to do quick tests of the API. You can also use this method from your code.
cURL requests can be made in most languages, which means you can make the calls direct in command line or assign the result to a variable in the language of your choice. Look here for some quick tips on using cURL.
Let's try a test request, with a simple sentence. We'll run it through the analyzeEntities endpoint.
In your terminal or command line interface, enter the following command:
curl -X POST \
-H "Authorization: Bearer "$(gcloud auth application-default print-access-token) \
-H "Content-Type: application/json; charset=utf-8" \
--data "{
'document':{
'type':'PLAIN_TEXT',
'content':'John McCarthy is one of the founding fathers of artificial intelligence.'
},
'encodingType':'UTF8'
}" "https://language.googleapis.com/v1/documents:analyzeEntities"You should see a JSON result after executing. You may get prompted the first time you use this to activate the API or allow access. You can answer 'yes' or 'y' to that prompt and it should return the JSON after that.
It will return an array of entries, similar to ones like this first one for the entry "John McCarthy".
{
"name": "John McCarthy",
"type": "PERSON",
"metadata": {
"wikipedia_url": "https://en.wikipedia.org/wiki/John_McCarthy_(computer_scientist)",
"mid": "/m/01svfj"
},
"salience": 0.40979216,
"mentions": [
{
"text": {
"content": "John McCarthy",
"beginOffset": 0
},
"type": "PROPER"
}
]
},Note: You could use a URL instead of content text in the content parameter of the cURL statement.
You can see in the sample entity listing, the name identified and the type, which the AI determined is a PERSON. It also found a Wikipedia match for the name and returned that. This can be useful, since you could use that URL as the content for a second request to the API and get even more entities and information on this one. You can also see the salience value at 0.4, which indicates a significant relative importance of the entity in the context of the text we provided. You can also see it is correctly identified as PROPER, which refers to the noun type (a proper noun), as well as how many occurrences (mentions) of the entity in the text.
The API will return values for all the key entities in the text you submit. This alone can be extremely useful for processing what a user might be communicating to your app. Regardless of what the sentence contained, there is a good chance it is about the person, John McCarthy, and we could look up some information for the user based on this alone. We could also respond in a way that reflects our understanding this statement refers to a person.
You can keep using this method to test out the calls we'll use. You can also set up local SDK in a language you prefer and integer into your app.
07. Install client library
Time to make a simple web-based app to demonstrate how to integrate the API into projects.
For NLP apps it is common to use Python or Node. To show the versatility of using the APIs, we'll use the PHP SDK. If you wish to tweak the code into a different language there is a great resource of SDKs here.
Start by making sure you have a project folder set up on your local or remote server. If you don't have it already, get Composer and install to your project folder. You may have Composer already installed globally and that is fine too.
Run the following Composer command to install the vendor files to your project:
php -r "copy('https://getcomposer.org/installer', 'composer-setup.php');"
php -r "if (hash_file('sha384', 'composer-setup.php') === '93b54496392c06277467 0ac18b134c3b3a95e5a5e5 c8f1a9f115f203b75bf9a129d5 daa8ba6a13e2cc8a1da080 6388a8') { echo 'Installer verified'; } else { echo 'Installer corrupt'; unlink('composer-setup.php'); } echo PHP_EOL;"
php composer-setup.php
php -r "unlink('composer-setup.php');"
php composer.phar require google/cloud-languageComposer makes a vendor folder in your project folder and installs all the dependencies for you.
If you get stuck setting this up and want to use PHP, you can check out this resource on installing Composer.
08. Create a new file
If you're following along in PHP, create a new PHP file in your project folder. Set it up however you like but include a simple HTML form to quickly submit text through.
Here is an example PHP file with the form:
<!DOCTYPE html>
<html>
<head>
<title>NET - NLP Tutorial</title>
</head>
<body>
<form>
<p><input type='text' id="content" name="content" placeholder="What can I analyze?" /></p>
<p><input type='submit' name='submit' id='submit' value='analyze'></p>
</form>
<div class="results">
<?php
// php code goes here //
if(empty($_GET['content'])) { die(); }
$content = $_GET['content'];
?>
</div>
</body>
</html>The code includes a basic HTML file with a form, along with a placeholder for your PHP code. The code starts by simply checking for the existence of the content variable (submitted from the form). If it's not submitted yet, it just exits and does nothing.
09. Make the environment variable
Similar to the step we did previously when using the command line cURL call, we need to set the GOOGLE_APPLICATION_CREDENTIALS variable. This is essential to getting it to authenticate.
In PHP we use the putenv command to set an environment variable. The authentication created by the SDK expires, so you need to include this in your code for it to grab it and set it each time.
Add this code next in your PHP code:
putenv('GOOGLE_APPLICATION_CREDENTIALS=/Users/richardmattka/Downloads/NLP Tutorial 1-1027228343dc.json');Replace the path and file name as you did before with your own.
10. Initialise the library
Next, add the library and initialise the LanguageClient class in your code. Add this code next to your PHP code section:
require __DIR__ . '/vendor/autoload.php';
use Google\Cloud\Language\LanguageClient;
$projectId = 'nlp-tutorial-1-1543506531329';
$language = new LanguageClient([
'projectId' => $projectId
]);Start by requiring the vendor autoload. This is similar in Python or Node if you require your dependencies. Import the LanguageClient next, to make use of the class. Define your projectId. If you aren't sure what this is, you can look it up in your GCP console, where you set up the project originally. Finally, create a new LanguageClient object using your projectId and assign it to the $language variable.
11. Analyse the entities
Now you're ready to start using the NLP API in your code. You can submit the content from the form to the API and get the result. For now you will just display the result as JSON to the screen. In practice you could assess the results and use them any way you wish. You could respond to the user based on the results, look up more information or execute tasks.
To recap, entity analysis will return information about the 'what' or the 'things' found in the text.
$result = $language->analyzeEntities($content);
foreach($result->entities() as $e){
echo "<div class='result'>";
$result = json_encode($e, JSON_PRETTY_PRINT);
echo $result;
echo "</div>";
}This code submits the content from the submitted form to the analyzeEntities endpoint and stores the result in the $result variable. Then, you iterate over the list of entities returned from $result->entities(). To make it a little more readable, you can format it as JSON before outputting to the screen. Again, this is just an example to show you how to use it. You could process it and react to the results however you need.
12. Analyse the sentiment
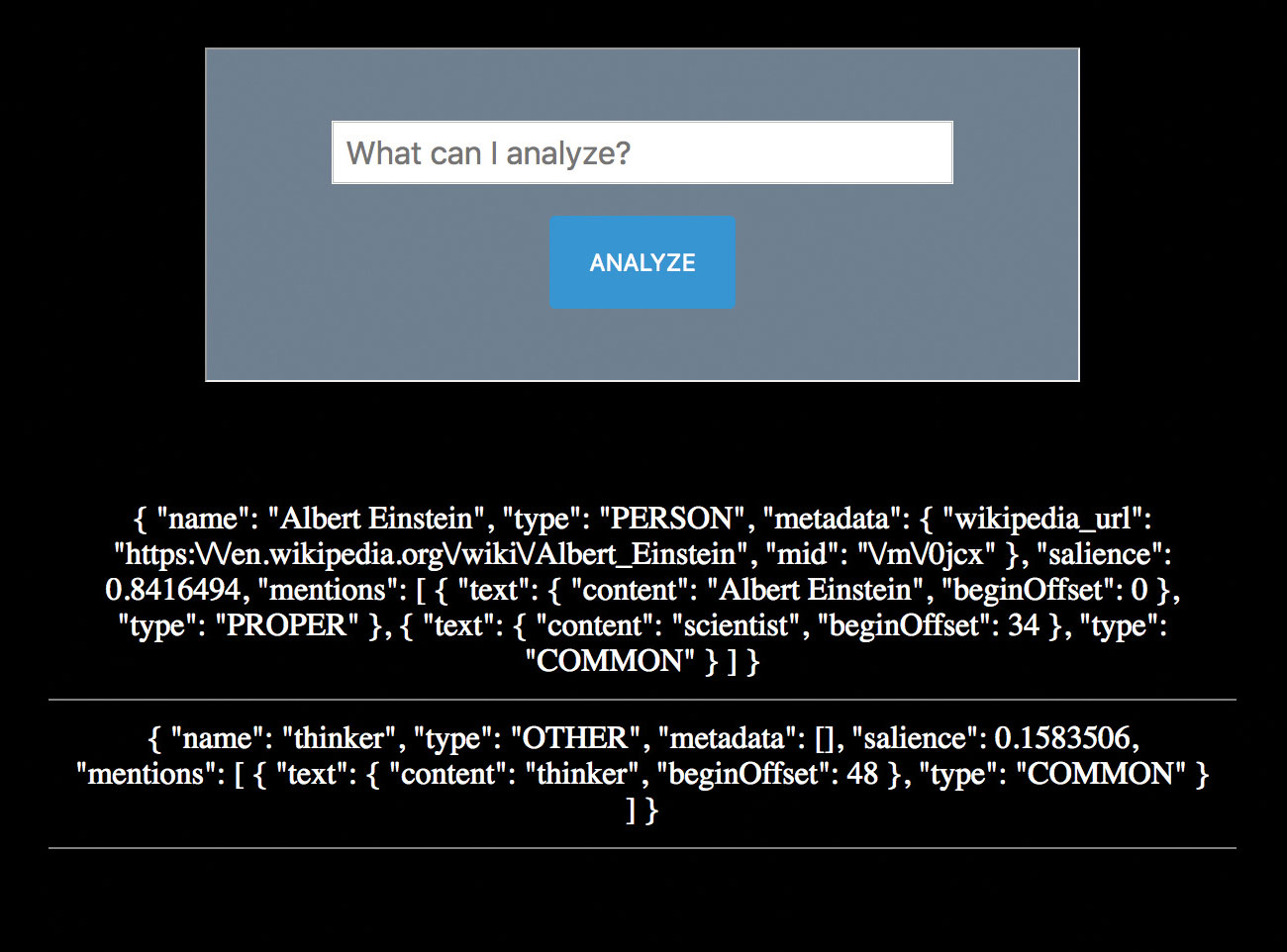
Instead of knowing the 'what' of the content, it can also be valuable to know the sentiment. How does the user feel? How do they feel about the entities in their communications?
Update the code to use the analyzeEntitySentiment endpoint. This will assess both the entities as before but also return a sentiment score for each one.
$result = $language->analyzeEntitySentiment($content);
foreach($result->entities() as $e){
echo "<div class='result'>";
$result = json_encode($e, JSON_PRETTY_PRINT);
echo $result;
echo "</div>";
}Testing with the content via the form, "Star Wars is the best movie of all time.", you will see a result similar to this:
{ "name": "Star Wars", "type": "WORK_OF_ART", "metadata": { "mid": "\/m\/06mmr", "wikipedia_url": "https:\/\/en.wikipedia.org\/wiki\/Star_Wars" }, "salience": 0.63493526, "mentions": [ { "text": { "content": "Star Wars", "beginOffset": 0 }, "type": "PROPER", "sentiment": { "magnitude": 0.6, "score": 0.6 } } ], "sentiment": { "magnitude": 0.6, "score": 0.6 } }
{ "name": "movie", "type": "WORK_OF_ART", "metadata": [], "salience": 0.36506474, "mentions": [ { "text": { "content": "movie", "beginOffset": 22 }, "type": "COMMON", "sentiment": { "magnitude": 0.9, "score": 0.9 } } ], "sentiment": { "magnitude": 0.9, "score": 0.9 } }This shows a positive sentiment score of significant value. Not only do you now know the key words the user is communicating but also how they feel about it. Your app can respond appropriately based on this data. You've got a clear identification of "Star Wars" as the primary subject with high salience. You've got a Wikipedia link to grab more information if you want to run that URL back through the same API call. You also know the user is feeling positive about it. You can even see the statement weights the positive sentiment on the quality of it as a movie. Very cool.
Parting thoughts
Try experimenting with other endpoints. Specifically, check out the analyzeSyntax and classifyText endpoints. These give you even more parts of speech data and classification of the content entities.
This article was originally published in issue 315 of net, the world's best-selling magazine for web designers and developers. Buy issue 315 here or subscribe here.
Related articles:

Thank you for reading 5 articles this month* Join now for unlimited access
Enjoy your first month for just £1 / $1 / €1
*Read 5 free articles per month without a subscription
Join now for unlimited access
Try first month for just £1 / $1 / €1

Richard is an award-winning interactive technologist, designer and developer. He specialises in creating interactive worlds with science-fiction themes, exploring the synergy between human and machine. He has also written regular articles for Net Magazine, and Web Designer Magazine on a range of exciting topics across the world of tech, including artificial intelligence, VFX, 3D and more.
